
Think about the last time you made an online purchase or booked a doctor’s appointment. Behind the scenes, there’s a lot of data flying around – things like your address, payment info, or medical history. If that data is wrong or outdated, it can cause delays, mistakes, or even security issues. Traditional ways of managing data are like fixing a leak after the water has already spilled – slow and reactive.
What if there was a smarter way? A system that keeps an eye on data all the time, spots problems right away, and even fixes them automatically? That’s what this paper is all about: a vision for a new, AI-powered approach to keep data clean, accurate, and reliable – without waiting for errors to pile up.
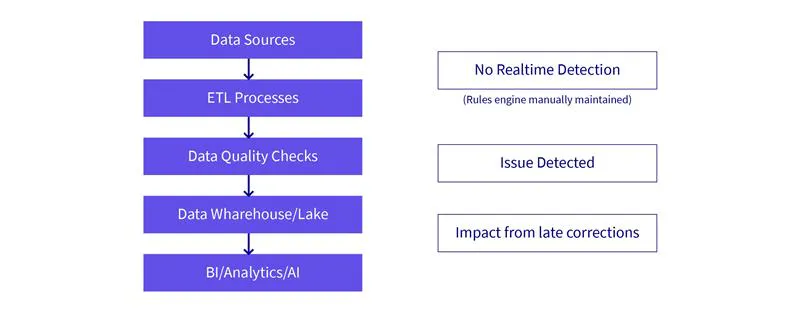
The demand for trustworthy, timely, and clean data has never been higher. Traditional data quality management relies heavily on manual rule creation, data stewards, and reactive clean-up. This process is slow, error-prone, and fails to keep pace with today’s real-time, high-velocity data environments.
We propose a paradigm shift: Autonomous Data Quality — an AI-driven, self-healing ecosystem that not only detects issues but intelligently corrects them using business context, historical patterns, and real-time feedback. This paper outlines the architecture, use cases, and Collibra integration plan to bring this ground-breaking concept to life in the enterprise landscape.
The Problem with Today’s Data Quality
- Manual rule management: Static, rule-based systems that require constant human updates.
- Lack of context: Data quality checks do not understand business meaning or downstream use.
- Delayed feedback: Quality issues are only detected after damage is done.
- Data silos: Each team solves quality problems in isolation.
- Limited automation: Fixes are reactive, not autonomous.
- Human bottlenecks: Data stewards become overwhelmed with growing volume & complexity.
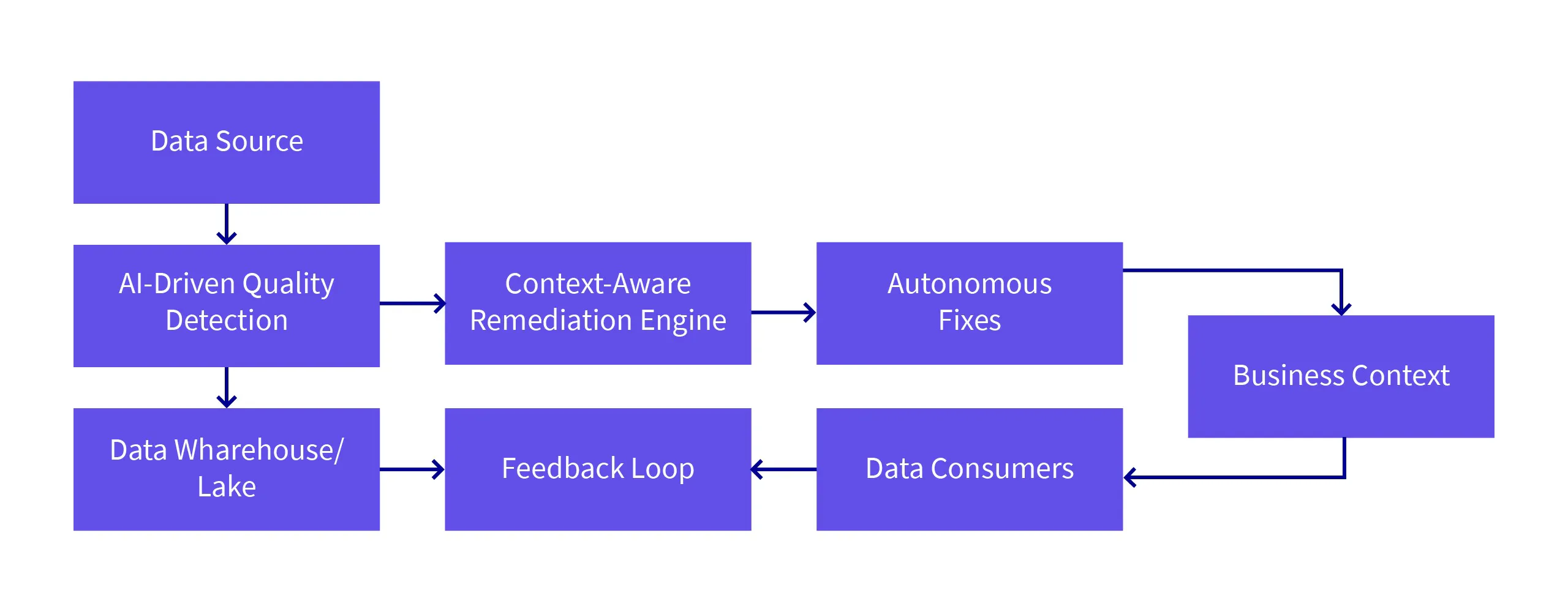
Self-Healing Data Ecosystem
A Self-Healing Data Ecosystem is an autonomous, AI-driven framework that continuously monitors, identifies, and corrects data quality issues in real-time without manual intervention. Using advanced machine learning models, feedback loops, and data context-awareness, this system can autonomously fix anomalies and ensure data quality at scale.
Key Features
- Real-Time Issue Detection: Detects data quality issues such as anomalies, duplicates, missing values, and inconsistencies immediately as they arise.
- Context-Aware Correction: Corrects issues using business rules, historical data trends, and integration with downstream applications, ensuring fixes are contextually appropriate.
- Reinforcement Learning Feedback Loop: Continuously improves data correction models based on feedback from data consumers and business stakeholders.
- No Manual Rule Creation: The system does not require predefined rules. It learns and adapts to changing data environments and business requirements.
- Autonomous Data Stewardship: Moves beyond traditional data stewardship by automatically resolving issues that would otherwise require manual intervention.
In contrast to traditional reactive approaches, a self-healing data ecosystem continuously adapts and fixes quality issues as they arise, all while considering the business context and user feedback. This makes it both proactive and scalable, ensuring the data used by businesses is always high-quality, consistent, and reliable.
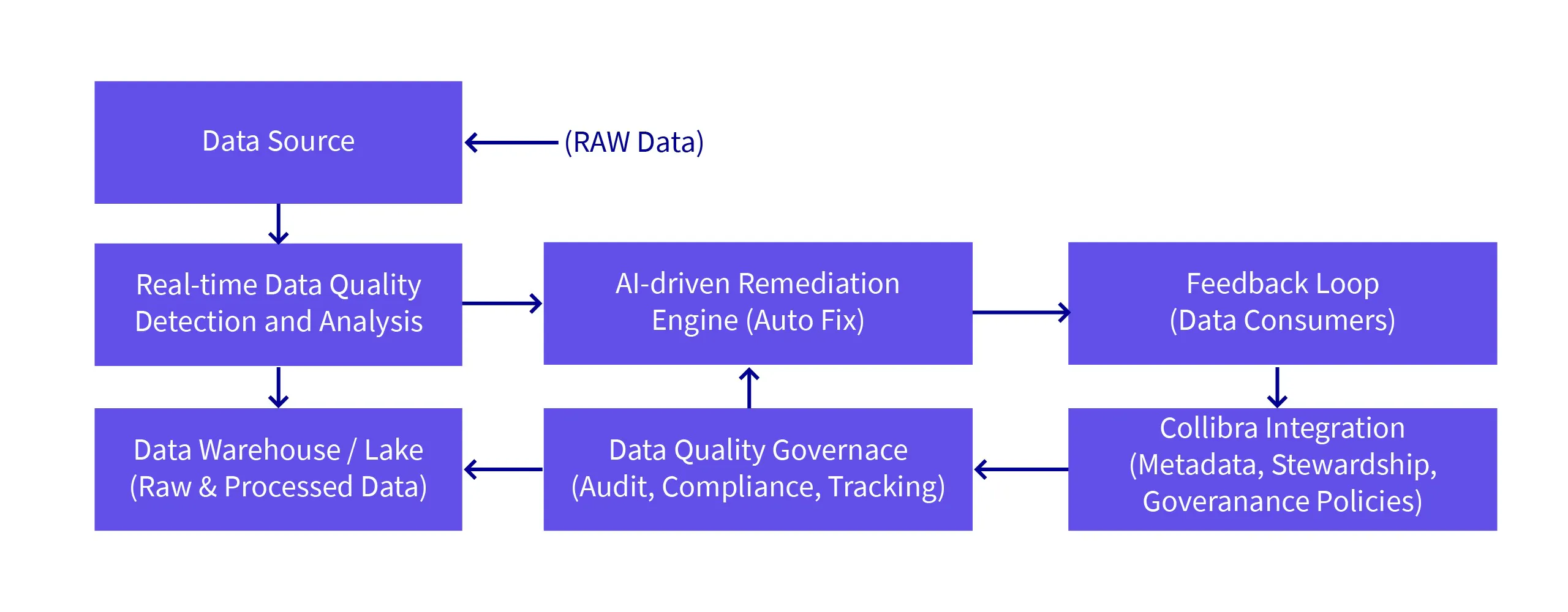
Proposed Architecture of the Self-Healing Data Ecosystem
This architecture enables the autonomous detection and real-time correction of data quality issues, integrated with existing data governance frameworks for compliance, auditing, and oversight. The use of AI and feedback loops ensures the system evolves and adapts to new data patterns, improving over time.
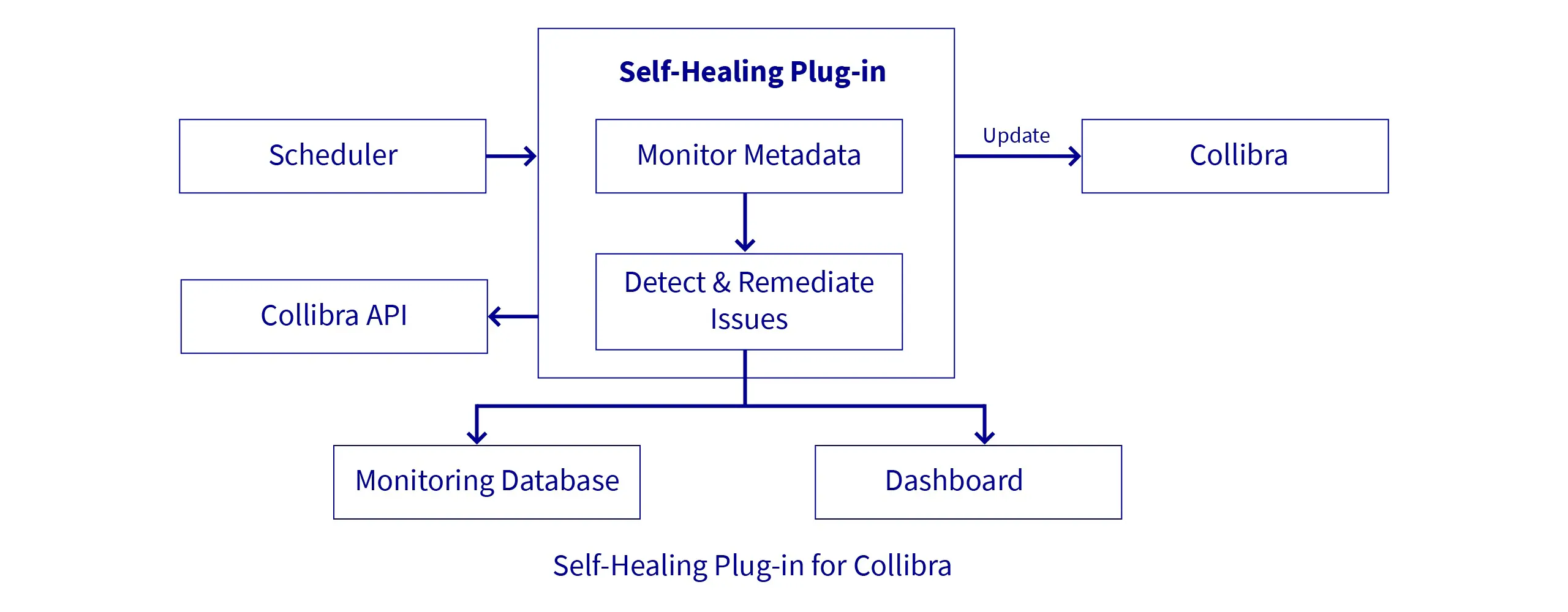
Proof of Concept (POC) or Demo
Real-World Use Cases
Use Case 1: Financial Services – Real-Time Fraud Detection
Industry Problem
In the financial services industry, maintaining the integrity of transactional data is critical. Data quality issues such as missing or inconsistent transaction details can lead to financial errors, compliance failures, and fraud detection lapses.
Solution with Self-Healing Data Ecosystem
- AI-driven anomaly detection continuously monitors transaction data in real time for inconsistencies, such as sudden large transactions or missing data fields.
- The contextual remediation engine automatically corrects missing or incorrect transaction data by cross-referencing with external data sources (e.g., customer accounts, historical trends).
- Feedback loop from compliance officers and fraud detection teams helps improve anomaly detection over time, ensuring models stay relevant to emerging fraud patterns.
Impact
- Reduced human intervention for fraud detection.
- Improved accuracy in identifying fraudulent transactions.
- Real-time fixes that prevent financial errors and fraud.
Use Case 2: Healthcare – Ensuring Accurate Patient Data
Industry Problem
In healthcare, patient data quality is vital for patient care, billing, and compliance with regulations. Errors such as duplicate records, missing medical history, or inconsistent diagnoses can lead to treatment mistakes and compliance violations.
Solution with Self-Healing Data Ecosystem
- Real-time monitoring detects missing or outdated patient data across electronic health records (EHR) systems.
- The AI remediation engine automatically resolves discrepancies by cross-referencing with reliable sources, such as patient interactions, appointments, or external databases.
- Feedback from healthcare providers helps refine data correction models to adapt to different specialties and regional standards.
Impact
- Improved patient care through accurate, up-to-date medical records.
- Reduced risk of errors in patient treatment and billing.
- Streamlined compliance with healthcare regulations such as HIPAA.
Approach to Implement
Develop a functional prototype that demonstrates the capabilities of a self-healing data quality system, integrated with Collibra for governance, metadata management, and stakeholder collaboration.
Implementation Steps
Set Up Data Environment
- Deploy a data lake or warehouse (e.g., Amazon S3, Google BigQuery) to store raw and processed data.
Develop Data Pipelines
- Configure data ingestion pipelines to process incoming data streams.
- Integrate data validation steps to detect quality issues in real-time.
Build AI Models
- Train models on historical data to identify patterns and anomalies.
- Implement correction algorithms that suggest or apply fixes based on learned patterns.
Integrate with Collibra
- Use Collibra's Integration API to send data quality findings and remediation actions to the Collibra Platform.
- Update data catalogues with corrected data and associated metadata.
- Initiate workflows for data stewards to review corrections when necessary.
Develop Monitoring Dashboards
- Create visualizations to track data quality trends, correction effectiveness, and system performance.
- Allow users to drill down into specific data quality issues and remediation actions.
Collibra Integration Details
Integration API Usage
- Push data quality scores and findings to Collibra without relying on Collibra Edge.
- Update data catalogues and metadata in real-time to reflect the current state of data quality.
Workflow Automation
- Trigger Collibra workflows for data stewardship tasks when automated corrections require human oversight.
- Notify relevant stakeholders of significant data quality events or changes.
Governance and Compliance
- Maintain audit trails of data quality issues and remediation actions within Collibra.
- Ensure compliance with data governance policies by integrating correction actions into Collibra's governance framework.
Key Benefits
Proactive Data Quality Management
- Before: Traditional approaches are reactive, relying on scheduled scans or manual validations.
- With Self-Healing: Continuous, real-time monitoring and fixing reduce the window of exposure to bad data.
Automated Issue Remediation
- Eliminates up to 60–80% of manual data correction effort.
- Uses AI to recommend or apply context-aware fixes, reducing human errors.
Feedback-Driven Evolution
- System learns from data steward inputs, improving over time.
- Incorporates business context dynamically, enhancing precision.
Collibra Synergy
- Metadata-aware AI corrections via Collibra catalogues and lineage.
- All auto-remediation actions are logged and auditable within Collibra.
- Workflow triggers enable optional manual intervention when confidence is low.
Compliance & Auditability
- Full traceability of changes—who fixed what, when, and why.
- Supports regulatory compliance (GDPR, HIPAA, etc.) by enforcing data governance policies automatically.
Cross-Platform Integration
- Works across hybrid environments (on-prem, cloud, SaaS).
- Compatible with common tools like Spark, Kafka, Airflow, Collibra, and Snowflake.
Conclusion
The Self-Healing Data Ecosystem, when integrated with platforms like Collibra, represents a transformative leap in data governance and quality management. By moving beyond traditional reactive models and introducing AI-driven, context-aware automation, this system can detect, correct, and learn from data anomalies in near real-time—without compromising governance, traceability, or human oversight.
This solution not only ensures data remains accurate and usable but also aligns closely with enterprise governance goals such as compliance, auditability, and operational efficiency. Its architecture ensures adaptability across domains while its tight integration with Collibra makes it governance-ready from day one.
Author

Sumit Mittal
Consultant, Data Management & Governance, Data, AI & Automation Services